Documentation
projects/infernoFrom Editor to Production: A Simple Static Publish Pipeline
Most content systems treat publishing as a button.
But under the hood, publishing is a data pipeline problem.
You’re not just “deploying a site.” You are:
- transforming structured data
- materializing a snapshot
- compiling it into a static artifact
- and shipping it to a CDN
This post walks through a simple, real-world publish pipeline—from editor → build → deploy—and the tradeoffs behind it.
The Core Idea
At a high level, publishing looks like this:
Editor → API → Build → DeployBut that hides the real complexity.
A more accurate version:
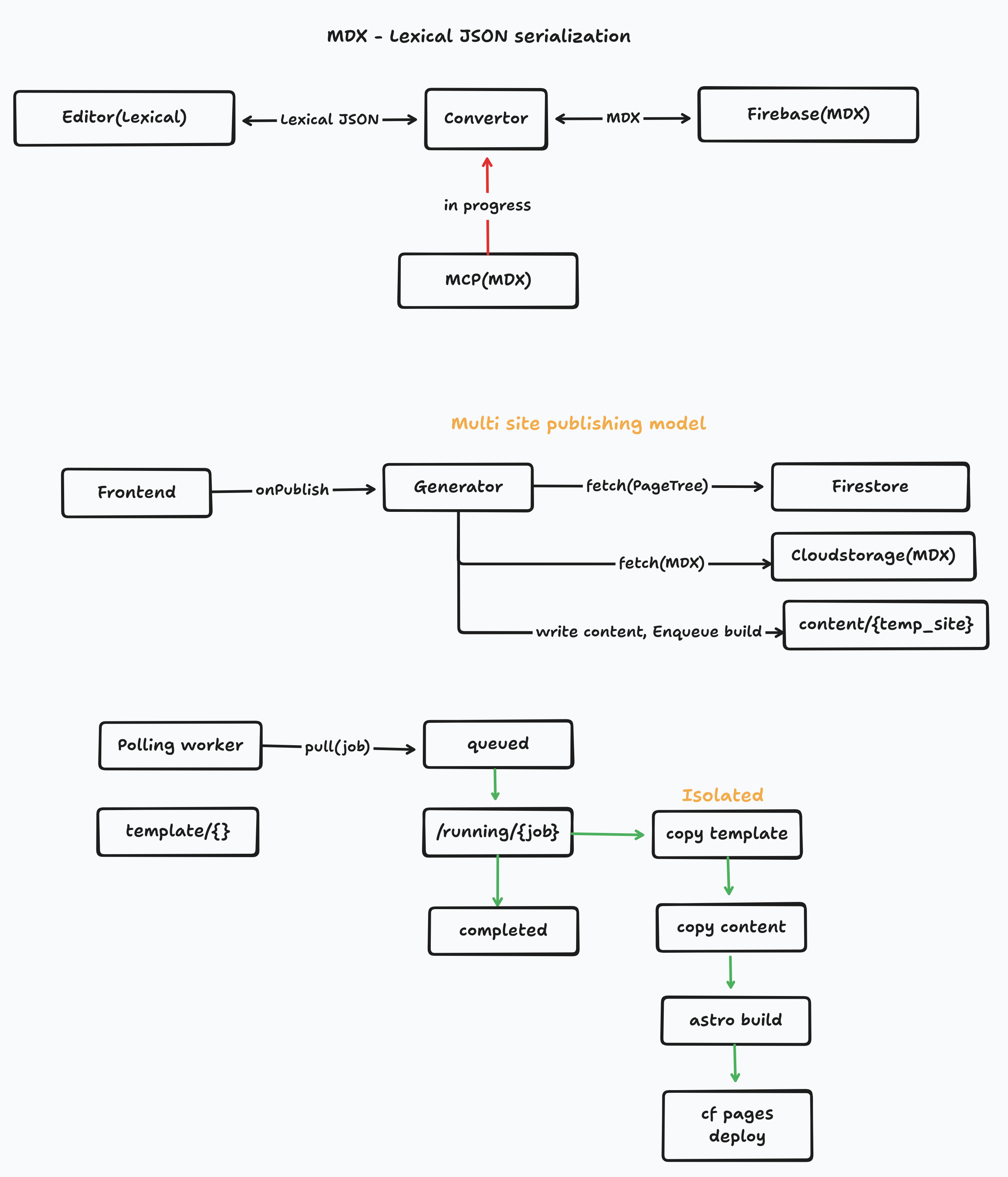
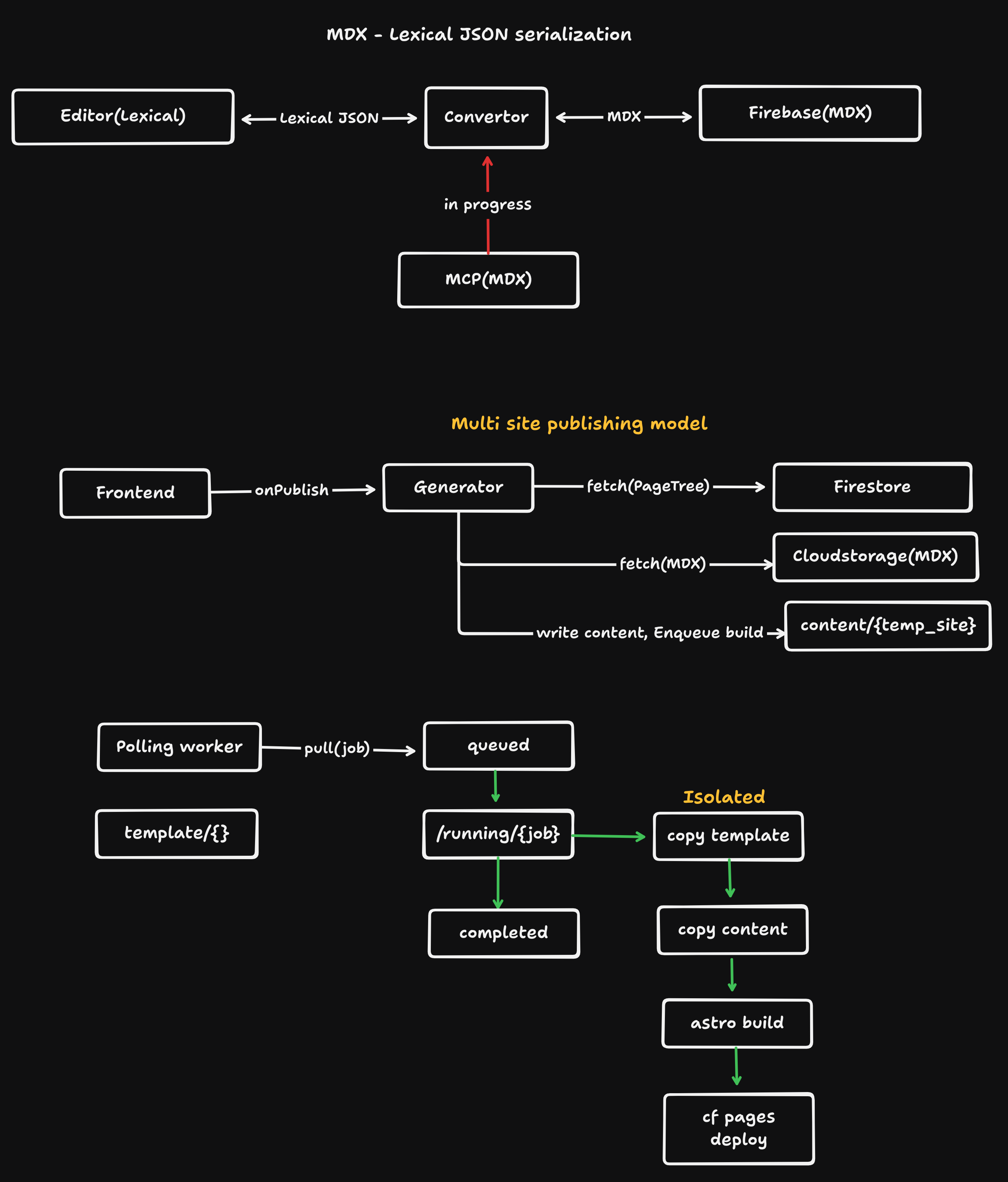
Content (Firestore + Storage)
↓
Publish Trigger (Firebase Function)
↓
Build System (Vercel)
↓
Fetch → Transform → Write → Compile (Astro)
↓
Deploy (CDN)This separation is important:
- Content layer → stores structured data
- Build layer → converts data → website
- Deploy layer → serves the result
Step 1 — Content is not a Website
In this system:
- Page structure lives in Firestore (page tree)
- Content lives as MDX in storage
At this stage, nothing is a “website” yet.
It’s just:
- nodes
- relationships
- structured text
This distinction matters because:
Step 2 — Publish is an Event
Publishing starts here:
/publishSite → Firebase Function → triggerDeployThe function:
- authenticates the request
- triggers a new build on Vercel using a deploy hook
This is an event-driven trigger, not a long-running process.
Why this is good:
- no infrastructure to manage
- no background workers needed
- build system handles execution
Step 3 — Build System Pulls Data
Once Vercel starts the build:
fetchTree → fetchMdx → writeToContentThe build does three things:
1. Fetch page structure
- navigation
- hierarchy
- routing info
2. Fetch content
- MDX blobs from storage
3. Materialize files
- write everything into
/content - prepare it for the static site generator
This step converts:
remote data → local filesystemThat transition is critical because most static generators (like Astro) expect files, not APIs.
Step 4 — Compile with Astro
Now the system becomes deterministic:
Astro build → static HTML + assetsGiven the same input files:
- the output will always be identical
This is a key property:
Step 5 — Deploy
After build:
Static output → CDN (via Vercel)Now the site is:
- globally cached
- fast
- serverless
Why This Design Works
This pipeline is intentionally simple:
1. No runtime rendering
- everything is precomputed
- cheaper and faster
2. Clear separation of concerns
- Firebase → data
- Vercel → compute + deploy
- Astro → rendering
3. Deterministic builds
- easier to debug
- reproducible outputs
Tradeoffs
This approach isn’t perfect.
Full rebuild on every publish
- even small changes trigger full builds
- becomes slow at scale
External dependency during build
- Firebase must be available
- network latency affects build time
No incremental updates (yet)
- no partial rebuilds
- no caching layer
What Comes Next
As systems grow, this pipeline evolves into:
queue → worker → build → deployWith:
- job states (queued, running, failed)
- incremental builds
- content snapshots
- multi-site support
But that complexity is not needed early.
Final Thought
Publishing is not a UI feature—it’s a data pipeline with a compiler at the end.
Once you see it that way:
- design decisions become clearer
- tradeoffs become explicit
- and scaling becomes manageable
Start simple.
Make it deterministic.
Add complexity only when the system demands it.